K-Nearest Neighbors
K-Nearest Neighbors, vaak afgekort als KNN, is een van de meest fundamentele en intuïtieve algoritmes binnen Machine Learning.
1. Wat is het?
Section titled “1. Wat is het?”KNN is een algoritme voor Supervised Learning. In tegenstelling tot veel andere algoritmes, leert het niet door een complex model te trainen, maar door de data simpelweg te onthouden (“Lazy Learner”).
Het wordt gebruikt voor twee hoofdtaken:
- Classificatie: Het voorspellen van een categorie (bijv. Is deze e-mail spam of niet?).
- Regressie: Het voorspellen van een numerieke waarde (bijv. Wat is de geschatte huizenprijs?).
2. Hoe werkt het?
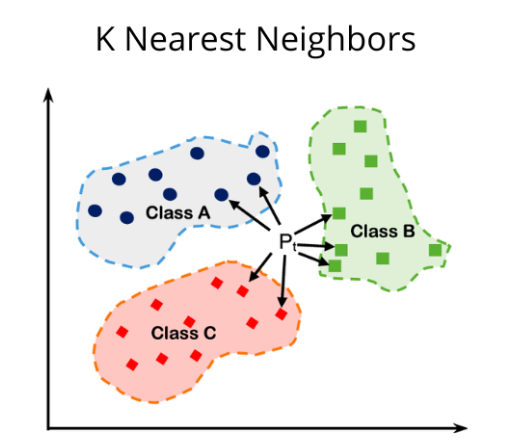
Section titled “2. Hoe werkt het?”Stel je wilt een nieuw datapunt (een nieuwe waarneming) classificeren. Het algoritme volgt deze stappen:
- Kies de parameter K: Bepaal het aantal buren (
K) waarnaar gekeken moet worden (bijvoorbeeldK=5). - Bereken de afstand: Het algoritme berekent de afstand tussen het nieuwe punt en alle andere punten in de dataset. De meest gebruikte methode is de Euclidische afstand:
d(x, y) = sqrt{sum_{i=1}^{n} (x_i - y_i)^2}- Vind de dichtstbijzijnde buren: Selecteer de
Kpunten met de kleinste afstand tot het nieuwe punt. - Maak de beslissing:
- Bij Classificatie: Laat de buren stemmen (“Majority Voting”). De categorie die het meest voorkomt onder de buren wint.
- Bij Regressie: Bereken het gemiddelde van de waarden van de buren.
3. De cruciale rol van K
Section titled “3. De cruciale rol van K”De keuze van K bepaalt de prestaties van het model:
- K is te klein (bijv. K=1): Het model is erg gevoelig voor ruis (noise). Een toevallige uitschieter kan de voorspelling direct fout maken (Overfitting).
- K is te groot: Het model wordt te vlak en mist de lokale structuren en nuances in de data (Underfitting).
- Tip: Kies vaak een oneven getal voor $K$ (3, 5, 7) om een gelijkspel (stakende stemmen) bij classificatie te voorkomen.
4. Voor- en Nadelen
Section titled “4. Voor- en Nadelen”| Voordelen | Nadelen |
|---|---|
| Eenvoudig: Zeer makkelijk te begrijpen en uit te leggen aan niet-technische mensen. | Traag bij veel data: Omdat het voor elke voorspelling de afstand tot alle punten moet berekenen, is het traag bij grote datasets. |
| Geen trainingstijd: Het opslaan van de data is de training. | Gevoelig voor schaal: Variabelen met grote getallen (bv. salaris van 50.000) domineren variabelen met kleine getallen (bv. leeftijd van 30). Normalisatie (scaling) van data is vereist. |
| Flexibel: Kan zowel lineaire als niet-lineaire relaties aan. | Geheugenintensief: De hele dataset moet in het geheugen geladen blijven. |
5. Voorbeeld
Section titled “5. Voorbeeld”Movie Recommendation System
Streaming platforms zoals Netflix of Spotify gebruiken principes die lijken op KNN.
Stel dat jij de films The Matrix en Inception leuk vindt. Het algoritme zoekt andere gebruikers (“buren”) die deze films óók leuk vonden. Als de meerderheid van die buren vervolgens de film Interstellar hoog waardeert, zal het algoritme Interstellar aan jou aanbevelen.
6. Implementatie (Scikit-Learn)
Section titled “6. Implementatie (Scikit-Learn)”Hieronder een voorbeeld met de bekende Iris-dataset.
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.metrics import accuracy_score
# 1. Data ladeniris = load_iris()X = iris.datay = iris.target
# 2. Data splitsen in training en test set (80% training, 20% test)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. Data schalen (CRUCIAAL voor KNN)# Omdat KNN met afstanden werkt, moeten alle features dezelfde schaal hebben.scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
# 4. Model initialiseren en trainen# We kiezen K=5knn = KNeighborsClassifier(n_neighbors=5)knn.fit(X_train, y_train)
# 5. Voorspelleny_pred = knn.predict(X_test)
# 6. Evaluerenaccuracy = accuracy_score(y_test, y_pred)print(f"Nauwkeurigheid van het model: {accuracy * 100:.2f}%")